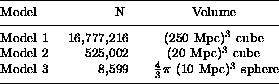According to current cosmological theory, much of the mass in the universe is in the form of so-called dark matter whose only significant interaction is gravitational [7]. Estimates are complicated by a number of difficult-to-measure parameters, but it is likely that dark matter constitutes between 20% and 98% of the mass of the universe. During the evolution of the universe, this dark matter forms dense objects, called halos, due to gravitational instability. Within these halos, the dark matter is supported against further collapse by random motions. The normal matter in the universe collects at the centers of these halos, where star formation leads to the existence of luminous galaxies and other observable phenomena.
A detailed analytic understanding of the evolution of the dark matter is hampered by the highly non-linear nature of the problem, and the complexity of the structures formed. Hence numerical methods have become a very important tool for understanding this evolution, and for comparing cosmological theories with astronomical observations. In N-body simulations, a piece of the Universe is represented by a set of N discrete particles, which can be interpreted as a Monte Carlo sampling of the vastly more numerous dark matter particles. Each particle has a position, a velocity, and a mass. The particle masses are set at the initial time and remain fixed; the particle positions and velocities are numerically integrated forward in time under the influence of the gravitational field of all of the particles. Simulations with larger N are desirable because the sampling is more complete. Larger N also gives larger dynamic range, i.e., the ratio of largest to smallest scales which can be addressed in a single simulation. This is important, for example, for investigating small-scale structure in simulations with a volume large enough to sample a representative region of the universe [15], or for better resolution of substructure in simulations of clusters of galaxies [4].
The output of these N-body simulations is a list of the three-dimensional positions and velocities of all the bodies in the system. The raw data themselves do not provide direct physical insight -- i.e., the individual bodies do not correspond to any particular object in the physical universe. Before drawing physical conclusions, the physically meaningful halos must be located and cataloged. Halos are stable, persistent, gravitationally bound collections of bodies that correspond to the locations at which galaxies or clusters of galaxies form. Halos may contain other halos in a hierarchy. This represents the idea that a small collection of bodies may be stable and gravitationally bound, e.g., the solar system, yet it may be contained within a much larger stable system, e.g., the Milky Way galaxy. (In practice, the hierarchies that form in current computer models have nowhere near the range of length and time scales of this illustrative example.) Once a list of halos is compiled, their properties, e.g., mass, location, velocity, shape, angular momentum, etc., may be compared statistically with those of observed galaxies. This is the standard methodology in cosmological simulations.
Halo finding is essentially a hierarchical clustering problem, where the number of clusters is very large and is not known in advance. As such, the techniques that are presented here in the context of astrophysical data reduction may find application in other fields where very large spatial data sets must be analyzed. Most of the techniques presented are not specific to astrophysical problems and are based on counting, neighbor-finding and density estimation, so they may have direct analogs in other problem domains. We also report on techniques that rely on problem-specific knowledge, e.g., the evaporation criterion discussed in section 3.2. While the specific physical concept of binding energy may be inappropriate for other disciplines, it illustrates the power of using domain-specific knowledge to craft appropriate statistical criteria.
Recently, systems with N larger than 322 million have been simulated on massively parallel computers [14]. These large simulations produce correspondingly large datasets, posing a challenge for analysis, which has traditionally been done on workstations. Practical considerations like available memory, reasonable turnaround time, and a desire to study time-dependent processes make it increasingly desirable for critical data analysis tasks also to run on parallel machines. The ``Halo World'' project is developing a set of parallel tools for detailed analysis of halo objects from very large N-body gravitational simulations, in preparation for correlation with future deep space object sky surveys such as the Sloan Digital Sky Survey (SDSS). We expect the output of future simulations to approach terabytes, consisting of hundreds of ``snapshots'' each of several gigabytes.
The two methods presented here address the problem of halo finding. Halos coincide with peaks in the underlying density field, but not all peaks are stable. A density peak's stability depends on the velocities of its constituent particles. An individual particle is gravitationally bound to the density peak if its velocity is small enough that the particle is confined by the gravity of the density peak to remain in the spatial region of the peak. The density peak as a whole is gravitationally bound if enough particles are bound so that the density peak persists over time.
Strictly speaking, halos should be defined in the six-dimensional
phase space that includes both velocities and positions. In practice,
halos are identified as clusters in three-dimensional position space,
and then are refined and possibly rejected
if they do not meet the stability criterion in
the six-dimensional phase space.
In fact, the stability criterion itself is often never evaluated.
Instead, peaks are accepted if they are sufficiently large, c.f.,
![]() in Section 3.
This is justified by noting
that in practice,
most density peaks form by gravitational collapse,
and as a result are automatically bound.
The important exceptions are those that arise from noise fluctuations in
the discrete sampling of the underlying distribution.
These fluctuations will result in density peaks which are not
bound, which we refer to as spurious halos.
The size criterion implicitly relies on the
fact that large chance fluctuations are extremely unlikely, so that
any observed cluster above a certain size is almost certainly
a genuine halo.
in Section 3.
This is justified by noting
that in practice,
most density peaks form by gravitational collapse,
and as a result are automatically bound.
The important exceptions are those that arise from noise fluctuations in
the discrete sampling of the underlying distribution.
These fluctuations will result in density peaks which are not
bound, which we refer to as spurious halos.
The size criterion implicitly relies on the
fact that large chance fluctuations are extremely unlikely, so that
any observed cluster above a certain size is almost certainly
a genuine halo.
The complexity of the spatial, velocity and density structure of the data is illustrated in the left hand panels of Figure 1. The halos are the distinct clusters of points that are supported against gravity by the `random' velocities of the particles. The magnitude of the problem is illustrated by Figure 5, which shows the results of halo finding in Model 1. The original data has 400 times as many particles. The number of particles in each halo ranges from ten up to tens of thousands. New simulation data sets are larger by a factor of about 20, placing proportionally larger demands on computational resources.
The Halo World research is developing its data analysis software to run on the most cost effective parallel computers available, clusters of commodity personal computers -- ``Piles-of-PCs'' [2]. Although no more than the cost of a high-end scientific workstation, clustered PCs can retain the hundreds of gigabytes of data required for this problem in local secondary storage, and deliver in excess of a gigaflops sustained performance. The algorithmic approach to be taken is in part driven by two factors related to this class of system. Because the simulation data set is so large, it must be managed from secondary storage rather than held in main memory. Therefore, out-of-core solution methods will be employed for extracting halos from simulation data. They require the programmer or library designer to grapple with the long latencies and large block sizes associated with disk access -- kilobytes of data are typically delivered in milliseconds, but smaller transfers cannot be made appreciably faster. Because performance of these systems is modest, even at a few gigaflops, an innovative algorithm is being implemented that mixes spatial and time domain extraction techniques.
The halo finding methods have been applied to real data sets obtained from
cosmological simulations.
Table 1 lists the basic parameters of
simulations which have been analyzed and will be referred to later.
The Megaparsec is the conventional unit of distance in
cosmology. 1 Mpc = 3.26 ![]() light years. A 250Mpc cube
contains about 5 million times the mass of our own Milky Way galaxy.
Thus, the individual particles in model 1 are about one third the size
of the Milky Way galaxy, and the halos that are extracted from the model
will represent galaxies and clusters of galaxies ranging in mass from
approximately that of our galaxy to several hundred times as large.
Models 2 and 3 are
sub-regions extracted from larger simulations.
The results from Model 1 have been applied to the
study of elliptical galaxies in [8].
light years. A 250Mpc cube
contains about 5 million times the mass of our own Milky Way galaxy.
Thus, the individual particles in model 1 are about one third the size
of the Milky Way galaxy, and the halos that are extracted from the model
will represent galaxies and clusters of galaxies ranging in mass from
approximately that of our galaxy to several hundred times as large.
Models 2 and 3 are
sub-regions extracted from larger simulations.
The results from Model 1 have been applied to the
study of elliptical galaxies in [8].
In the next section we describe the computational platform on which Halo World executes. Then we describe the friends of friends (FOF) halo finding method in Section 3, and note some shortcomings. This motivates the subsequent description of the new IsoDen method in Section 4, based on kernel density estimation [11]. Section 5 explains how the two methods have been implemented on parallel computers. Section 6 presents timing results on a distributed memory parallel computer with up to 512 processors. Finally, Section 7 contains some specific plans for development of an out-of-core implementation and a mechanism for tracking halos in time without recomputing them from scratch.